Lab 6 - Spatial Indexing#
Th. 07.11.2024 15:00-17:00
1 Installation of BeautifulSoup#
Beautiful Soup is a library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
2 Inverted Indexing#
In this section we will first create an inverted index and then query with the created index. In order to achieve the first step, we will first retrieve data from Wikipedia about 5 cities/towns in Austria. Here we will also need to retrieve their point coordinates for later spatial indexing.
2.1 Create an Inverted Index#
import wikipedia ## for getting Wikipedia summaries
## while during installation the package name is BeautifulSoup4,
## here it is still called BeautifulSoup when being imported
from bs4 import BeautifulSoup
import requests ## used along with BeautifulSoup
from geopy.geocoders import ArcGIS ## for geocoding city/town names
import spacy ## for text processing
import geopandas as gpd ## for spatial indexing
## for the later query with spatial indexing
from shapely.geometry import Point, box
poi_list = ['Vienna','Salzburg','Linz','Innsbruck','Hallstatt']
poi_wikipedia_list = []
for poi in poi_list:
summary = wikipedia.summary(poi + ', Austria') ## adding Austria in the search will help return more accurate results
summary = summary.replace('\n','')
url = "https://en.wikipedia.org/wiki/" + poi
req = requests.get(url).text
soup = BeautifulSoup(req)
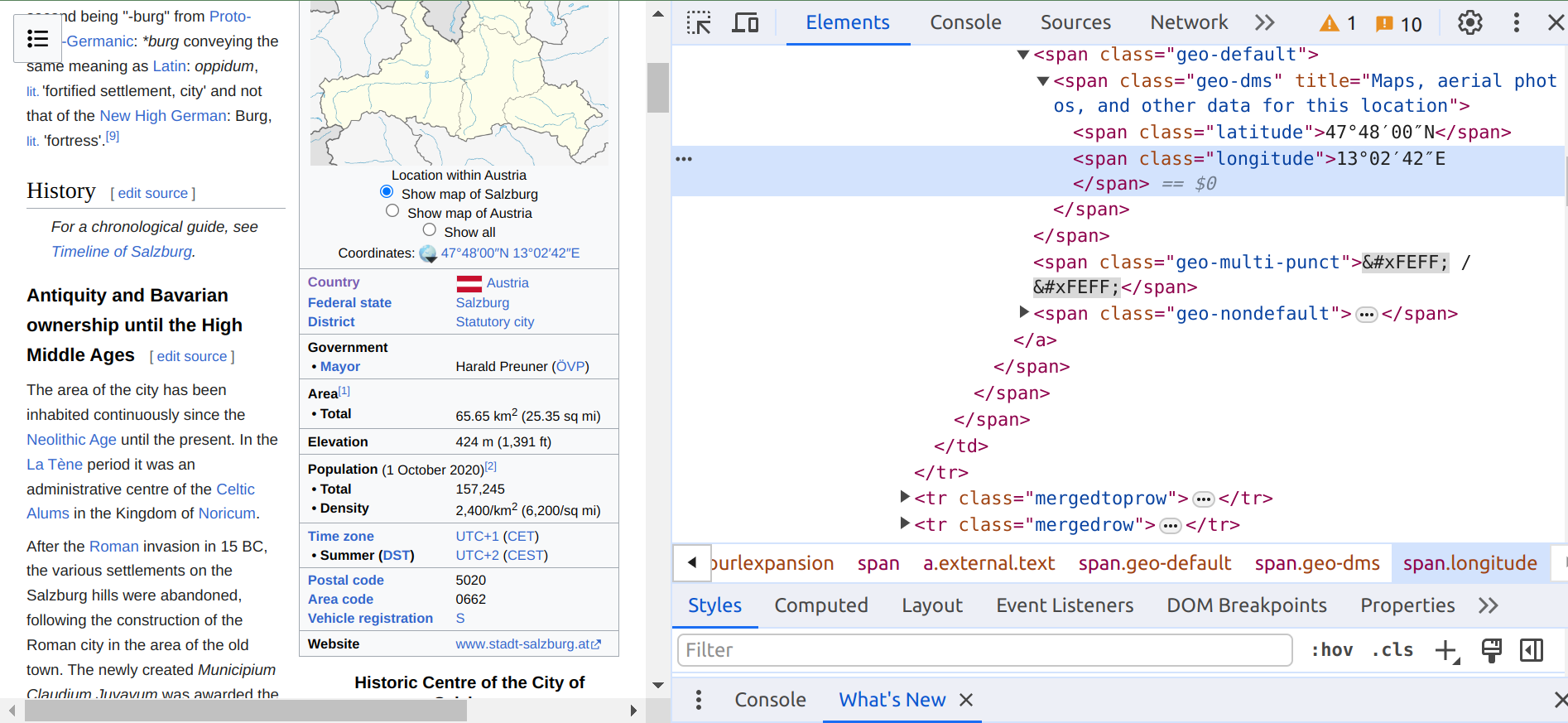
latitude = soup.find("span", {"class": "latitude"})
longitude = soup.find("span", {"class": "longitude"})
poi_wikipedia_list.append({'summary': summary, 'latitude': latitude.text, 'longitude': longitude.text})
In the code block above, what BeautifulSoup is looking for the element that has a <span> tag and a latitude or longitude class in an HTML webpage. Below is an example of Salzburg’s Wikipedia webpage.
nlp = spacy.load("en_core_web_sm") ## load an English trained pipeline
## use a set instead of a list to store tokens from a document collection
## a set makes sure there is no duplicate elements
token_set = set()
## use the built-in enumerate() function to get the counter and the item when iterating a list
for index, item in enumerate(poi_wikipedia_list):
summary = item['summary']
## get only the lowercase token after lemmatization (https://spacy.io/usage/linguistic-features#lemmatization)
## stop words are not considered during this process (https://en.wikipedia.org/wiki/Stop_word)
## and only tokens containing alphabetic characters are included (https://spacy.io/api/token)
tokens = [token.lemma_.lower() for token in nlp(summary) if token.lemma_.lower() not in nlp.Defaults.stop_words and token.is_alpha]
poi_wikipedia_list[index]['tokens'] = tokens
token_set = token_set.union(set(tokens)) ## use the union method to merge two sets
print(token_set)
## inverted_index is a dictionary
## each key-value pair in inverted_index is a term and its corresponding list of document ids
inverted_index = {}
for token in token_set:
inverted_index[token] = []
for index, item in enumerate(poi_wikipedia_list):
if token in item['tokens']:
inverted_index[token].append(index)
print(inverted_index)
2.2 Query with Inverted Indexing#
Next we are going to use a query to search for relevant documents. The example query is cities associated with Alps.
query = 'cities associated with Alps'
result_index_set = set()
for index, token in enumerate(nlp(query)):
if token.lemma_.lower() not in nlp.Defaults.stop_words and token.is_alpha:
## use the try and except blocks to handle errors such as KeyError
## KeyError will happen if a token in the query does not exist in the keys of the inverted index
## https://www.w3schools.com/python/python_try_except.asp
try:
print('The token \'', token, '\' appears in ', set(inverted_index[token.lemma_.lower()]))
if index == 0:
## use the union method to populate the set at the beginning
result_index_set = result_index_set.union(set(inverted_index[token.lemma_.lower()]))
else:
## use the intersection method to find out overlaps between the set and a new set
## the new set is the associated list of document ids with the next token (in the query)
result_index_set = result_index_set.intersection(set(inverted_index[token.lemma_.lower()]))
except KeyError:
continue
The returned set of document ids by the given query is as follows.
result_index_set
3 Spatial Indexing#
For spatial indexing, we will rely on the built-in STRtree implementation of GeoPandas.
3.1 Create a Spatial Index#
To create a spatial index, we need to use the coordinates retrieved before. We also need to convert these coordinates into decimal degrees, and then create a GeoDataFrame that includes city names, summaries, and geometries.
def convert2decimal(num, islatorlon): ## a function for converting coordinates into decimal degrees
num = num.replace('°',',')
num = num.replace('′',',')
num = num.replace('″',',')
num = num.split(',')
decimal = float(num[0]) + float(num[1])/60 + float(num[2])/3600
if islatorlon == 'lat':
if num[3] == 'S': ## include a minus sign for locations in the southern hemisphere
return -decimal
else:
return decimal
else:
if num[3] == 'W': ## include a minus sign for locations to the west of the prime meridian
return -decimal
else:
return decimal
## a dictionary for storing relevant city information
poi_wikipedia_dict = {'name':[],'summary':[],'geometry':[]}
for i in range(len(poi_list)):
poi_wikipedia_dict['name'].append(poi_list[i])
poi_wikipedia_dict['summary'].append(poi_wikipedia_list[i]['summary'])
lat = poi_wikipedia_list[i]['latitude']
lon = poi_wikipedia_list[i]['longitude']
lat = convert2decimal(lat,'lat')
lon = convert2decimal(lon,'lon')
poi_wikipedia_dict['geometry'].append(Point(lon, lat)) ## create a Point object
## create a GeoDataFrame from the dictionary
## make sure to set the crs (coordinate reference system)
df_poi_wikipedia = gpd.GeoDataFrame(data = poi_wikipedia_dict, columns = ['name', 'summary','geometry'], crs = 'EPSG:4326')
df_poi_wikipedia.head()
## generate the spatial index
spatial_index = df_poi_wikipedia.sindex
spatial_index
spatial_index.size ## check the size of the spatial index
3.2 Query with Spatial Indexing#
Here we will use five close-by cities to generate queries about them in relation to the created spatial index. To do so, we need to first geocode them.
query_locations = ['Graz','Prague','Budapest','Munich','Zurich']
geolocator_arcgis = ArcGIS()
query_lon_list = []
query_lat_list = []
for address in query_locations:
location = geolocator_arcgis.geocode(address)
query_lon_list.append(location.longitude)
query_lat_list.append(location.latitude)
## we will generate a GeoSeries from their coordinates
query_geoseries = gpd.GeoSeries(gpd.points_from_xy(query_lon_list, query_lat_list))
## not only we can find the nearest city to a random Point...
spatial_index.nearest(Point(14.5501, 47.5162))
## but also we can find the nearest city of a list of Points in the created GeoSeries
spatial_index.nearest(query_geoseries)
In the output above, the first subarray of indices contains input geometry indices. The second subarray of indices contains tree geometry indices.
## we can also create a bounding box to find out what cities are within it
spatial_index.query(box(9.47996951665, 46.4318173285, 16.9796667823, 49.0390742051))
spatial_index.valid_query_predicates ## check the valid query predicates
## use the 'contains' predicate with return all cities
spatial_index.query(box(9.47996951665, 46.4318173285, 16.9796667823, 49.0390742051), predicate = 'contains')
## use the 'within' predicate with return none
spatial_index.query(box(9.47996951665, 46.4318173285, 16.9796667823, 49.0390742051), predicate = 'within')
In addition to ‘contains’, other predicates can be chosen depending on the geometries of indexed and queried objects.
Submission#
Run the codes above and submit the .ipynb file along with answers to the following questions:
Based on the indices returned by
result_index_set, what are the cities ‘associated with Alps’?Try to use a different query with inverted indexing, what are the indices returned? Do the results make sense?
Based on the index pairs returned by
spatial_index.nearest(query_geoseries), for each city inquery_locationswhat is its nearest city inpoi_list?Try to use a different bounding box for
spatial_index.query(), what are the cities that will be returned?